Oracle企业级数据恢复指导手册
一、 前言
数据库紧急恢复作为灾难恢复及数据安全管理中的重要一环,虽然经过合理的前期规划、设计,日常检查与监控的预防,服务器软硬件的常规检查等措施,正常情况下不会遇到需要紧急恢复的情况,但有备无患,这里整理罗列常见的数据库灾难恢复场景及具体恢复步骤、说明如下,作为Oracle数据库恢复指导。对数据库的操作必须抱有敬畏之心,小心谨慎,避免不必要的人为灾难。
二、 重做日志组损坏恢复
(一) 丢失重做日志组中的一个成员(成员数>1)
- 查看日志成员的状态,此时丢失文件成员的状态被标记为INVALID,找到这个invaild的成员。
SELECT GROUP#, STATUS, MEMBER FROM V$LOGFILE WHERE STATUS='INVALID'
- 通过下面命令删除受损的日志成员,路径为上面member字段值
Sql>alter database drop logfile member ‘/u01/app/oracle/oradata/test/redo01.log’;
- 执行下面命令增加日志组成员,group 1为第1步结果中显示的GROUP#
Sql>alter database add logfile member ‘/u01/app/oracle/oradata/test/redo01.log’ to group 1;
- 使用下面查询来查看连接日志的状态。
Select group#,status,member from v$logfile order by group#;
日志文件成员的状态会是NULL。
(二) 丢失重做日志组中的所有成员
当发生丢失重做日志组中所有成员时,这种情况视问题组的具体情况而定解决方案,这里引入Oracle官方介绍附在下面,英文比较简单,不做翻译。
Recovering After the Loss of an Online Redo Log Group
| If the Group Is... | Then... | And You Should... |
| Inactive | It is not needed for crash recovery | Clear the archived or unarchived group. |
| Active | It is needed for crash recovery | Attempt to issue a checkpoint and clear the log; if impossible, then you must either use Flashback Database or restore a backup and perform incomplete recovery up to the most recent available redo log. |
| Current | It is the redo log that the database is currently writing to | Attempt to clear the log; if impossible, then you must either use Flashback Database or restore a backup and perform incomplete recovery up to the most recent available redo log. |
1) 判断有问题的GROUP是active还是inactive
1. SELECT GROUP#, STATUS, MEMBER FROM V$LOGFILE;
通过上述SQL查看有问题的重做日志组成员所属组。
2. SELECT GROUP#, MEMBERS, STATUS, ARCHIVED FROM V$LOG;
返回结果查看问题GROUP,如果为inactive,即为丢失非当前日志组所有成员,如果为ACTIVE,则为丢失当前日志组所有成员
2) 丢失非当前日志组所有成员
可以在数据库OPEN或mount状态下执行clear an inactive redo log group。Clear命令会重建组成员(不管成员被删除还是损坏)。这种情况不会造成数据的丢失。具体操作步骤取决于损坏的GROUP是否已归档。
- To clear an inactive, online redo log group that has been archived
假设数据库已经关闭,OPEN状态下仅需执行第2步;
1. Startup mount
2. ALTER DATABASE CLEAR LOGFILE GROUP 2;这里假设查到有问题的GROUP 为GROUP 2
3. Alter database open;
- To clear an inactive, online redo log group that has not been archived
清空重用一个未归档的重做日志,这个操作会使此重做日志中the last change时间之前的所有备份无效,日志点重新计算。需重新进行备份,以还原到操作点之后的时间。
假设数据库已经关闭,假如数据库是OPEN状态,仅需执行2和4
1. Startup mount
2. ALTER DATABASE CLEAR LOGFILE unarchived GROUP 2;这里假设查到有问题的GROUP 为GROUP 2
3. Alter database open;
4. 尽快进行数据库完整备份
3) 丢失当前日志组所有成员,且正常(干净)关闭DB
进行恢复会丢失当前日志组中未归档的数据,只能恢复到最近可用的redolog1. Startup mount2. Recover database until cancel;3. Alter databse open resetlogs;4. 尽快安排数据库完整备份
4) 丢失当前日志组所有成员,非干净关闭,则需要
1. Startup mount2. 首先在spfile中添加参数:Alter system set _allow_resetlogs_corruption=true scope=spfile;3. Shutdown immediate;4. Startup mount5. Recover database until cancel;6. Alter databse open resetlogs;7. 尽快安排数据库完整备份8. 修改_allow_resetlogs_corruption回默认的false
5) 丢失非当前日志组所有成员,且未归档的一个测试
以开发库测试(linux)环境
删除重做日志非当前组GROUP 4,手工切换几次日志,切换到GROUP 4时,切换失败,数据库会依然使用GROUP 3。
SQL> alter database clear logfile group 4;
alter database clear logfile group 4
ERROR at line 1:
ORA-00350: log 4 of instance orcl (thread 1) needs to be archived
ORA-00312: online log 4 thread 1: '/home/oracle/oradata/orcl/redo4.log'
ORA-00312: online log 4 thread 1: '/home/oracle/oradata/orcl/redo4_new.log'
SQL> alter database drop logfile group 4;
alter database drop logfile group 4
ERROR at line 1:
ORA-00350: log 4 of instance orcl (thread 1) needs to be archived
ORA-00312: online log 4 thread 1: '/home/oracle/oradata/orcl/redo4.log'
ORA-00312: online log 4 thread 1: '/home/oracle/oradata/orcl/redo4_new.log'
删除或清空GROUP 4都提示需要归档,使用如下SQL取消归档,可能丢失一部分数据
SQL> alter database clear unarchived logfile group 4;
Database altered.
SQL> alter database drop logfile group 4;
Database altered.
SQL> alter database add logfile group 4('/home/oracle/oradata/orcl/redo4.log','/home/oracle/oradata/orcl/redo4_new.log');
Database altered.
警告日志中的说明:
Tue Apr 16 09:41:25 2013
alter database clear unarchived logfile group 4
WARNING! CLEARING REDO LOG WHICH HAS NOT BEEN ARCHIVED. BACKUPS TAKEN
BEFORE 04/16/2013 09:27:42 (CHANGE 13156893821) CANNOT BE USED FOR RECOVERY
(三) 防止重做日志故障的措施
采用多路复用措施,至少3个组,每个组成员数量2个。这里有个问题,比如我们的环境是建了REDOLOG1和REDOLOG2两个ASM磁盘组,不同成员放在不同的磁盘组上,然而实际上这2个磁盘组对应的还是同一个存储,只是不同的区域而已,所以我们目前的环境这种REDO多路径配置只是防止ASM磁盘组单点故障,稍微减少了同时损坏的可能,最完美的场景是在不同的物理磁盘上,这才是真正意义上防止redlolog成员的物理单点故障。
三、 控制文件损坏恢复
show parameter control 查看当前数据库的控制文件数量、存储位置
(一) 控制文件损坏,但至少还有一个可用
1) 复制恢复控制文件到默认位置
控制文件所在磁盘并未损坏,或已修复,则可执行如下操作恢复控制文件到默认位置
1. Shutdown abort2. Copy 控制文件替换损坏或丢失的控制文件3. Startup
2) 复制恢复控制文件到其它位置(如默认位置磁盘损坏)
控制文件所在磁盘损坏,暂无法修复,则需恢复控制文件到其他位置,操作如下
1. 备份下现有的pfile和spfile:Create pfile from spfile;2. Shutdown abort3. Copy 控制文件到其他位置4. 修改pfile文件INITSID.ORA文件,找到control_files=一行,修改其中的路径5. Startup pfile=’pfile路径’6. Create spfile from pfile
SQL> startup pfile='E:\app\molayunwei\product\11.2.0\dbhome_1\database\INITmbs7test.ORA'ORACLE 例程已经启动。Total System Global Area 6847938560 bytesFixed Size 2188768 bytesVariable Size 4697623072 bytesDatabase Buffers 2130706432 bytesRedo Buffers 17420288 bytes数据库装载完毕。数据库已经打开。SQL> create spfile from pfile;文件已创建。SQL> show parameter controlNAME TYPE------------------------------------ ----------------------VALUE------------------------------control_file_record_keep_time integer7control_files stringE:\APP\MOLAYUNWEI\ORADATA\MBS7TEST\CONTROL01.CTL, E:\APP\MOLAYUNWEI\ORADATA\MBS7TEST\MBS7DATA\CONTROL02.CTLcontrol_management_pack_access stringDIAGNOSTIC+TUNING
(二) 丢失全部控制文件,有控制文件备份
- Shutdown abort
- Rman targert /
- Set dbid 3656495157(这里就要求保留一份DBID列表select dbid from v$database)
- Startup nomount
- Restore controfile from autoback;或restore controlfile from ‘+fradata/控制文件备份路径’;
- Alter database mount
- Recover database using backup controlfile;
注意:这里由于只是丢失控制文件,而数据文件和redolog还在,所以只需提示用旧的控制文件恢复即可,这里主要用到了redolog的最后scn(on disk scn)进行完整恢复。
- 最后恢复完后Alter databse open;
(三) 系统掉电控制文件过旧
系统掉电后,控制文件没有来得及更新SCN,造成控制文与redolog里的信息不一致,而OPEN不了DB
方法一:(适用于归档或非归档模式)
重建控制文件
alter database backup controlfile to trace;
查看新生成的跟踪文件:/home/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_15472.trc
取第一部分noresetlog的控制文件脚本,以开发库为例,内容如下:
STARTUP NOMOUNT
CREATE CONTROLFILE REUSE DATABASE "ORCL" NORESETLOGS ARCHIVELOG
MAXLOGFILES 16
MAXLOGMEMBERS 3
MAXDATAFILES 100
MAXINSTANCES 8
MAXLOGHISTORY 1168
LOGFILE
GROUP 2 (
'/home/oracle/oradata/orcl/REDO02.LOG',
'/home/oracle/oradata/orcl/REDO02_new.LOG'
) SIZE 200M BLOCKSIZE 512,
GROUP 3 (
'/home/oracle/oradata/orcl/REDO03.LOG',
'/home/oracle/oradata/orcl/REDO03_new.LOG'
) SIZE 200M BLOCKSIZE 512,
GROUP 4 (
'/home/oracle/oradata/orcl/redo4.log',
'/home/oracle/oradata/orcl/redo4_new.log'
) SIZE 400M BLOCKSIZE 512
-- STANDBY LOGFILE
DATAFILE
'/home/oracle/oradata/orcl/system01.dbf',
'/home/oracle/oradata/orcl/sysaux01.dbf',
'/home/oracle/oradata/orcl/undotbs01.dbf',
'/home/oracle/oradata/orcl/users01.dbf',
'/home/oracle/oradata/orcl/devtest01.dbf',
'/home/oracle/oradata/orcl/Mola_Pur_Data01.dbf',
'/home/oracle/oradata/orcl/MOLA_PUR_Index01.dbf',
'/home/oracle/oradata/orcl/MOLA_WMS7_Data01.dbf',
'/home/oracle/oradata/orcl/MOLA_WMS7_Index01.dbf',
'/home/oracle/oradata/orcl/Mola_PCenter01.ora',
'/home/oracle/oradata/orcl/OPC_INDEX01.dbf',
'/home/oracle/oradata/orcl/OMS_DATA01',
'/home/oracle/oradata/orcl/OMS_Index01.ora',
'/home/oracle/oradata/orcl/ OMS_DATA01.ora',
'/home/oracle/oradata/orcl/FBS_DATA01.dbf',
'/home/oracle/oradata/orcl/CRM_DATA01',
'/home/oracle/oradata/orcl/CRM_IDX01',
'/home/oracle/oradata/orcl/CRM_DATA02',
'/home/oracle/oradata/orcl/msg_data01',
'/home/oracle/oradata/orcl/msg_idx01.dbf',
'/home/oracle/oradata/orcl/invoice_data01',
'/home/oracle/oradata/orcl/invoice_idx01.dbf',
'/home/oracle/oradata/orcl/ysxt_data01',
'/home/oracle/oradata/orcl/ysxt_idx01.dbf',
'/home/oracle/oradata/orcl/yfxt_data01',
'/home/oracle/oradata/orcl/yfxt_idx01.dbf',
'/home/oracle/oradata/orcl/Mola_SC_data01',
'/home/oracle/oradata/orcl/Mola_SC_idx01.dbf',
'/home/oracle/oradata/orcl/Mola_DMS_data01',
'/home/oracle/oradata/orcl/Mola_DMS_idx01.dbf',
'/home/oracle/oradata/orcl/Mola_DMSTemp_data01',
'/home/oracle/oradata/orcl/Mola_DMSTemp_idx01.dbf',
'/home/oracle/oradata/orcl/move_test_data01',
'/home/oracle/oradata/orcl/move_test_idx01.dbf',
'/home/oracle/oradata/orcl/pmc_dev_data01',
'/home/oracle/oradata/orcl/pmc_idx01.dbf',
'/home/oracle/oradata/orcl/PCM_DATA01.dbf',
'/home/oracle/oradata/orcl/PCM_Index01.dbf',
'/home/oracle/oradata/orcl/SMM_DATA',
'/home/oracle/oradata/orcl/SMM_INDEX01.ORA',
'/home/oracle/oradata/orcl/WSS_DEV_DATA01.dbf',
'/home/oracle/oradata/orcl/WSS_DEV_INDEX01.dbf',
'/home/oracle/oradata/orcl/HQS_DEV_DATA01.dbf',
'/home/oracle/oradata/orcl/HQS_DEV_INDEX01.dbf',
'/home/oracle/oradata/orcl/MSG_DATA2.dbf',
'/home/oracle/oradata/orcl/PMC_INDEX01.dbf',
'/home/oracle/oradata/orcl/OPC_DEV1_01',
'/home/oracle/oradata/orcl/edm_data',
'/home/oracle/oradata/orcl/O2Odata01.dbf',
'/home/oracle/oradata/orcl/O2Oidx01.dbf'
CHARACTER SET AL32UTF8
;
-- Configure RMAN configuration record 1
VARIABLE RECNO NUMBER;
EXECUTE :RECNO := SYS.DBMS_BACKUP_RESTORE.SETCONFIG('CONTROLFILE AUTOBACKUP','ON');
-- Configure RMAN configuration record 2
VARIABLE RECNO NUMBER;
EXECUTE :RECNO := SYS.DBMS_BACKUP_RESTORE.SETCONFIG('CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE','DISK TO ''/home/oracle/orabak/%
F''');
-- Configure RMAN configuration record 3
VARIABLE RECNO NUMBER;
EXECUTE :RECNO := SYS.DBMS_BACKUP_RESTORE.SETCONFIG('RETENTION POLICY','TO RECOVERY WINDOW OF 3 DAYS');
-- Configure RMAN configuration record 4
VARIABLE RECNO NUMBER;
EXECUTE :RECNO := SYS.DBMS_BACKUP_RESTORE.SETCONFIG('CHANNEL','DEVICE TYPE DISK FORMAT ''/home/oracle/orabak/%U''');
-- Configure RMAN configuration record 5
VARIABLE RECNO NUMBER;
EXECUTE :RECNO := SYS.DBMS_BACKUP_RESTORE.SETCONFIG('DEVICE TYPE','DISK BACKUP TYPE TO COMPRESSED BACKUPSET PARALLELISM 1');
-- Commands to re-create incarnation table
-- Below log names MUST be changed to existing filenames on
-- disk. Any one log file from each branch can be used to
-- re-create incarnation records.
-- ALTER DATABASE REGISTER LOGFILE '/home/oracle/flash_recovery_area/ORCL/archivelog/2013_11_19/o1_mf_1_1_%u_.arc';
-- ALTER DATABASE REGISTER LOGFILE '/home/oracle/flash_recovery_area/ORCL/archivelog/2013_11_19/o1_mf_1_1_%u_.arc';
-- Recovery is required if any of the datafiles are restored backups,
-- or if the last shutdown was not normal or immediate.
RECOVER DATABASE
-- All logs need archiving and a log switch is needed.
ALTER SYSTEM ARCHIVE LOG ALL;
-- Database can now be opened normally.
ALTER DATABASE OPEN;
-- Commands to add tempfiles to temporary tablespaces.
-- Online tempfiles have complete space information.
-- Other tempfiles may require adjustment.
ALTER TABLESPACE TEMP ADD TEMPFILE '/home/oracle/oradata/orcl/temp01.dbf' REUSE;
ALTER TABLESPACE DEVTEMPTS1 ADD TEMPFILE '/home/oracle/oradata/orcl/tempts1.dbf' REUSE;
-- End of tempfile additions.
注意:这里用noresetlogs方式打开的意义是,以redolog的最后scn为准,把其scn更新到控制文件里去,这样是不会丢数据的;反之用resetlogs方式打开,则重建所有redolog文件,数据库会丢失重做日志里的内容。
方法二:
如控制文件重建后依然打不开DB,如果数据非关键,可配置隐含参数跳过数据库一致性验证强行打开,方法如下:
- 先修改PFILE,增加隐含参数:_allow_resetlogs_corruption=true
- 然后用该参数文件打开数据库:
SQL>startup pfile=’pfile文件具体路径’;
- 然后把隐含参数从pfile文件中去掉后,重新用spfile启动后打开后,需立刻备份数据库。
(四) 丢失所有控制文件,但无备份
- 根据模拟环境等现存环境控制文件尝试手工生成控制文件
(五) 防止控制文件故障的措施
- 采用多路复用;
- 每天备份控制文件;
- 定期生成重建控制文件的脚本
- 定期备份SPFILE/PFILE参数文件到其他服务器保存
四、 参数文件和控制文件的恢复
如果不幸参数文件和控制文件被删除,需要从RMAN的备份集里恢复。
- 做这个操作有个前提,首先需要记录原数据库的DBID:
以下为erprac库的dbid:
SQL>select dbid from v$database;
DBID
---------
3656495157
以下为molarac库的dbid:
SQL> select dbid from v$database;
DBID
----------
2447564929
- 登录RMAN并进行以下操作:
sqlplus /nolog
conn /as sysdba
Startup nomount
RMAN TARGET /
RMAN>set dbid 3656495157
恢复参数文件:
RMAN>restore spfile from ‘+ORAFRA/erprac/autobackup/参数文件的备份路径’
例如在erprac上操作:
RMAN>restore spfile from ‘+ERPFRA/erprac/autobackup/2012_05_24/s_784123381.576.784123381’;
然后关闭数据库并启动至nomount状态:
RMAN>shutdown immediate
RMAN>startup nomount --重新用备份的参数文件启动
恢复控制文件:
RMAN>restore controlfile from ‘+fradata/控制文件备份路径’
例如在erprac1上操作:
RMAN>restore controlfile from ‘+ERPFRA/erprac/autobackup/2012_05_24/s_784123381.576.784123381’;
启动至mount模式并打开数据库:
RMAN>alter database mount;
RMAN>alter database open;
此时,有可能数据文件的状态不一致需要恢复,由于备份的控制文件的 SCN小于日志文件的SCN,因此需要用日志文件的SCN来恢复:
RMAN>recover database using backup controlfile;
最后再打开数据库:
RMAN>alter database open;
五、 数据库完全恢复
介质恢复可以借助的SQL:
SELECT FILE#, ERROR, ONLINE_STATUS, CHANGE#, TIME FROM V$RECOVER_FILE;
SELECT r.FILE# AS df#, d.NAME AS df_name, t.NAME AS tbsp_name,
d.STATUS, r.ERROR, r.CHANGE#, r.TIME
FROM V$RECOVER_FILE r, V$DATAFILE d, V$TABLESPACE t
WHERE t.TS# = d.TS#
AND d.FILE# = r.FILE#;
查询V$RECOVERY_LOG表找出还原所需的归档日志文件及路径
(一) 应用用户数据文件丢失
1) 恢复单个数据文件到原始位置(在线恢复)
当数据库在打开状态下,某个数据文件被删除的恢复方法(不包括system表空间,如果system表空间损坏,必须在mount模式下恢复):
操作步骤:
- 在open状态下运行RMAN管理器并恢复数据文件至当前状态:
RMAN> run {
sql 'alter database datafile 40 offline';
restore datafile 40;
recover datafile 40;
sql 'alter database datafile 40 online';
}
其中datafile 40为被误删的数据文件。
2) 模拟丢失OMS数据文件的实际恢复记录
环境:10.0.32.2 windows 2008 R2 测试前有全备 归档模式
关闭数据库后,手工删除OMS_DATA02.DBF文件,提示正在使用,关掉oracle服务,删除文件后,再启动服务.
只能启动到mount状态,无法OPEN,警告日志中也有此记录,表名文件号40出现问题
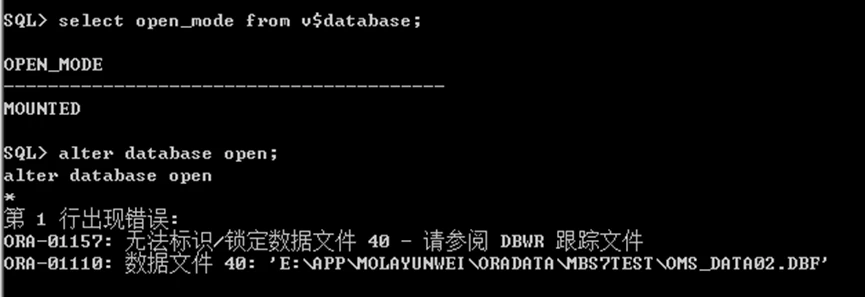
恢复损坏的文件,因为文件40已经是offline的了,所以与省了offline,online的过程:
- RMAN> restore datafile 40;
启动 restore 于 15-4月 -13
使用目标数据库控制文件替代恢复目录
分配的通道: ORA_DISK_1
通道 ORA_DISK_1: SID=541 设备类型=DISK
通道 ORA_DISK_1: 正在开始还原数据文件备份集
通道 ORA_DISK_1: 正在指定从备份集还原的数据文件
通道 ORA_DISK_1: 将数据文件 00040 还原到 E:\APP\MOLAYUNWEI\ORADATA\MBS7TEST\OMS_
DATA02.DBF
通道 ORA_DISK_1: 正在读取备份片段 E:\SQLBAK\BACKUPSET\LEVEL_0_MBS7TEST_20130415_
5_05O74T77_1_1---这个备份正是最近一次的0级备份
通道 ORA_DISK_1: 段句柄 = E:\SQLBAK\BACKUPSET\LEVEL_0_MBS7TEST_20130415_5_05O74T
77_1_1 标记 = LEVEL_0
通道 ORA_DISK_1: 已还原备份片段 1
通道 ORA_DISK_1: 还原完成, 用时: 00:03:25
完成 restore 于 15-4月 -13
- RMAN> recover datafile 40;
- Sql>alter database open
3) 恢复单个数据文件到新位置(在线恢复)
当数据文件所在的ASM磁盘组出现硬件故障,异常dismount,数据库不能打开,此时,可采用更改控制文件的方法,把备份的数据文件恢复至新的ASM磁盘组:
- 利用保留的spfile和控制文件挂载数据库:
sqlplus / as sysdba
SQL>startup mount
- 登陆RMAN管理器更改数据文件路径并恢复数据库至当前状态:
RMAN> run {
set newname for datafile 5 to '+oradata2';
restore datafile 5;
switch datafile all; ----更新控制文件,使路径变更生效
recover datafile 5;
sql 'alter database open';
}
注:这里新的ASM磁盘组为’+oradata2’,datafile 5为损坏的数据文件号,数据文件可以查询select * from dba_data_files,受损的文件号也可以在警告日志中查到。
附:添加ASM磁盘组的全过程,简单示意,详细过程可参考RAC实施方案
- 磁盘分区fdisk /dev/mapper/volume11 依次输入nàpà1à1
- 创建ASM磁盘[root@oracle01 ~]# /usr/sbin/oracleasm createdisk DATAVOL2 /dev/mapper/volume11p1
- 创建ASM磁盘组[grid@oracle01 ~]$ asmca
4) 模拟丢失OMS数据文件所在磁盘损坏实际恢复记录
如下测试是模拟数据所在磁盘损坏,恢复CRM应用数据到另外一个路径的操作过程。
环境准备:
Alter database datafile 10 offline;---offline CRM数据文件
Stop oracle服务
从操作系统层面删除datafile 10
启动oracle服务
下面恢复datafile 10到另外一个路径(路径所在文件夹是先提前创建好的):
RMAN> run {set newname for datafile 10 to 'E:\app\molayunwei\oradata\mbs7test\mbs7data\CRM_DATA.DBF';
2> restore datafile 10;
3> switch datafile all;
4> recover datafile 10;
5> sql 'alter database open'; --因为这次测试服务启动,数据完全启动正常,这步多余了
6> }
(二) Oracle表空间数据文件丢失或介质损坏
1) ORACLE用户表空间恢复
如果某个表空间的所有数据文件全部出现误删或介质损坏情况,那么当访问该表空间的对象时,会出现显示错误。可在OPEN状态下恢复:
- 当误删某表空间所有数据文件的情况下:
RMAN> run {
sql 'alter tablespace oms_data offline for recover';
restore tablespace oms_data;
recover tablespace oms_data;
sql 'alter tablespace oms_data online';
}
- 当某表空间的所有数据文件出现介质损坏的情况下:
RMAN> run {
sql 'alter tablespace t1 offline for recover';
set newname for datafile 4 to '+oradata2';
restore tablespace t1;
switch datafile all;
recover tablespace t1;
sql 'alter tablespace t1 online';
}
注:当数据文件意外删除或介质损坏时,offline时需要采用for recover选项,但正常脱机情况下无须加此选项。
2) ORACLE系统表空间恢复
系统表空间故障,会导致Oracle崩溃,需要在mount状态下恢复,如SYSTEM表空间数据库文件损坏,如下为操作步骤。
- Startup mount
- Rman targert /
- Restore tablespace SYSTEM;
- Recover tablespace SYSTEM;
- Alter database open
(三) 完全恢复整个数据库
当所有数据文件被管理员误删除或其他原因导致丢失,系统崩溃shutdown的情况下,需利用RMAN备份的文件和归档日志进行完全恢复:
操作步骤:
- 利用保留的spfile和控制文件挂载数据库:
sqlplus /as sysdba
SQL>startup mount
- 登陆RMAN管理器恢复数据文件并恢复至当前状态:
rman target /
RMAN>restore database;
RMAN>recover database;
- 打开数据库即可:
RMAN> sql 'alter database open';
六、 数据库不完全恢复
(一) 不完全恢复的步骤
- 关闭数据库完全备份下数据库目录,保护现场,以防还原出错
- 开数据库至mount状态:
Sqlplus /as sysdba
SQL>startup mount
- 进行不完全恢复:
- 基于时间点: restore database until time ‘2013-04-08 10:00:00’
- 基于撤销:recover database until cancel;
- 基于SCN: recover database until scn
SCN_TO_TIMESTAMP和TIMESTAMP_TO_SCN 这2个函数负责实现SCN和时间上的转换
- 打开数据库:
SQL>alter database open resetlogs;
- 备份数据库
(二) 模拟误删除用户表空间的恢复测试
模拟误删了用户表空间CRM_DATA,需要进行不完全恢复,如果只是误删除了CRM_DATA的数据库文件,可以进行完全恢复,整个表空间删除,则必须进行不完全会.
模拟环境准备:
SQL> drop tablespace crm_data including contents;
Tablespace dropped
在线恢复步骤:
- 从警告日志中查到删除操作发生时间:
Mon Apr 15 15:07:45 2013
drop tablespace CRM_DATA
ORA-1549 signalled during: drop tablespace CRM_DATA
Mon Apr 15 15:08:13 2013
drop tablespace crm_data including contents
Completed:
drop tablespace crm_data including contents
在15:15执行了如下操作
--15:15
insert into dba_wqw.test values(6,'e',sysdate);
commit;
- 15:20进行不完全恢复。
在非生产环境对数据库进行不完全恢复,还原到删除之前最近的一个时间点。
- 对生产环境进行增量备份level 1差异;
- 拷贝全备和增量备份到恢复服务器;
- 进行不完全恢复
- 将还原好后的CRM_DATA逻辑EXPDP导出,在生产环境执行IMPDP导入.
不完全恢复脚本如下:
run {
sql "alter session set nls_date_format=''yyyy-mm-dd hh24:mi:ss''"; --不然报格式不匹配
set until time '2013-04-15 15:08:10';
restore database;
recover database;
}
SQL> alter database open resetlogs; ---标识之前的归档日志失效了,重新开始
数据库已更改。
- 尽快完整备份数据库
七、 数据库闪回功能利用
- 闪回数据库的优势:
- 比备份还原数据库更快速,可针对单个表进行恢复;
- 可以提高数据容灾能力,非常方便解决误操作;
- 闪回数据库的局限:
- 不能解决介质故障,所以仍需备份;
- 如果控制文件被重建,则无法闪回数据库;
- 在resetllog恢复后无法使用;
- 不能闪回到一个比最早闪回日志还早的时间点
- 11G以前,闪回日志是不归档的,循环使用覆盖最早的,所以能闪回的时间点有限;
- 11G以后,Oracle 提供了一个这样的功能:闪回数据归档(Flashback Data Archive)。通过这一功能Oracle数据库可以将UNDO数据进行归档,从而提供全面的历史数据查询,目前我们环境暂时没使用这一特性。
- 闪回场景:
- Flashback database针对删除用户,清空表,批作业部分修改等
- Flashback drop针对删除表等
- Flashback table针对错误的where条件更新等
(一) 闪回表
针对错误的删除数据/修改数据,需要查询一段时间前的数据,可以用flashback table实现,但是如果该表发生DDL操作该表表结构,那么无法闪回到之前一段时间状态.
- 如下DDL操作会无法闪回表到DDL操作之前.
upgrading, moving, or truncating a table;
adding a constraint to a table, adding a table to a cluster;
modifying or dropping a column;
changing a column encryption key;
adding, dropping, merging, splitting, coalescing, or truncating a partition or subpartition (with the exception of adding a range partition);
- 如下对象不支持表闪回:
tables that are part of a cluster,
materialized views,
Advanced Queuing (AQ) tables,
static data dictionary tables,
system tables,
remote tables,
object tables,
nested tables,
individual table partitions or subpartitions
注:增加表字段,可以闪回
1) 闪回查询
- 闪回查询
- select * from table_name as of timestamp to_timestamp('2013-04-25 15:49:50','yyyy-mm-dd hh24:mi:ss');
2) 闪回表
- Flashback table
- 启用行移动alter table table_name enable row movement
- Select dbms_flashback.get_system_change_number from dual;
- 示例:flashback table table_name to timestamp to_timestamp('2013-04-25 15:50:50','yyyy-mm-dd hh24:mi:ss');
3) 闪回表删除
- Flashback drop(从回收站中闪回表)
可执行flashback drop的场景
- 闪回非系统表空间表
- 存储在本地管理表空间的表
- 未使用细粒度审计或虚拟私有数据库的表
- 未禁用回收站
- 没有清空删除表:drop table table_name purge
闪回脚本:
FALSHBACK TABLE table_name TO BEFORE DROP
如果原始名称已被现有对象使用
SQL> flashback table scott.dept7 to before drop rename to newtablename;
注:我们目前7.0 RAC数据库环境由于OGG的存在,已把回收站功能关闭。
4) Flashback table,flashback query,flashback drop案例
create table mbs7_smm.test(a int) tablespace smm_data
insert into mbs7_smm.test values(4);
commit;
--15:35
delete from mbs7_smm.test where a=4
select * from mbs7_smm.test
--闪回查询,对应误删除数据 flashback query 成功
select * from mbs7_smm.test as of timestamp to_timestamp('2013-04-25 15:33:20','yyyy-mm-dd hh24:mi:ss');
create table mbs7_smm.test2 as select * from mbs7_smm.test as of timestamp to_timestamp('2013-04-25 15:33:20','yyyy-mm-dd hh24:mi:ss');
--增加字段 15:54 闪回成功
alter table mbs7_smm.test add updatedate date
SELECT oldest_flashback_scn,oldest_flashback_time FROM V$FLASHBACK_DATABASE_LOG;
SELECT object_name, droptime FROM user_recyclebin
--15:56
insert into mbs7_smm.test values(7,sysdate);
insert into mbs7_smm.test values(8,sysdate);
--此时闪回一切正常
select * from mbs7_smm.test as of timestamp to_timestamp('2013-04-25 15:33:20','yyyy-mm-dd hh24:mi:ss');
select * from mbs7_smm.test as of timestamp to_timestamp('2013-04-25 15:56:20','yyyy-mm-dd hh24:mi:ss');
SELECT * FROM v$flashback_database_stat;
--flashback drop 15:59
drop table mbs7_smm.test
--因表结构改变,drop也可以算,所以无法闪回表,只能闪回删除
select * from mbs7_smm.test as of timestamp to_timestamp('2013-04-25 15:33:20','yyyy-mm-dd hh24:mi:ss');
select * from mbs7_smm.test as of timestamp to_timestamp('2013-04-25 15:56:20','yyyy-mm-dd hh24:mi:ss');
--闪回成功,闪回成功后,又可以闪回到之前的时间点 16:05
flashback table mbs7_smm.test TO BEFORE DROP;
select * from mbs7_smm.test as of timestamp to_timestamp('2013-04-25 15:33:20','yyyy-mm-dd hh24:mi:ss');
SELECT operation, undo_sql, table_name FROM FLASHBACK_TRANSACTION_QUERY where table_name='TEST'
--flashback table
alter table mbs7_smm.test enable row movement; --必须先启动行移动
flashback table mbs7_smm.test to timestamp to_timestamp('2013-04-25 15:56:20','yyyy-mm-dd hh24:mi:ss');
--flashback drop rename to newtablename 16:08
drop table mbs7_smm.test;
create table mbs7_smm.test(b int) tablespace smm_data;
flashback table mbs7_smm.test to before drop rename to test_0425flashbak;
select * from mbs7_smm.test_0425flashbak;--闪回成功
(二) 闪回表
1) 闪回数据库
- 闪回数据库
- --更改回话时间格式
SQL> alter session set NLS_DATE_FORMAT='yyyy-mm-dd hh24:mi:ss';
- --查数据库可闪回的最早时间
SELECT oldest_flashback_scn,oldest_flashback_time FROM V$FLASHBACK_DATABASE_LOG;
- Shutdown immediate
- Startup mount
- flashback database to timestamp to_timestamp('2013-04-25 13:22:44','yyyy-mm-dd hh24:mi:ss');
- 以只读模式打开数据库,验证恢复时间点是否正常alter database open read only;
- 验证完后shutdown immediate
- Startup mount
- Alter database open resetlogs;
- 闪回后尽快进行完备
2) Flashback database案例
闪回数据库实际操作案例
SQL> shutdown immediate;
数据库已经关闭。
已经卸载数据库。
ORACLE 例程已经关闭。
SQL> startup mount;
ORACLE 例程已经启动。
Total System Global Area 6847938560 bytes
Fixed Size 2188768 bytes
Variable Size 4697623072 bytes
Database Buffers 2130706432 bytes
Redo Buffers 17420288 bytes
数据库装载完毕。
SQL> SELECT oldest_flashback_scn,oldest_flashback_time FROM V$FLASHBACK_DATABASE
_LOG;
OLDEST_FLASHBACK_SCN OLDEST_FLASHBA
-------------------- --------------
1.3139E+10 24-4月 -13
SQL> flashback database to timestamp to_timestamp('2013-04-25 16:13:44','yyyy-mm
-dd hh24:mi:ss');
闪回完成。
SQL> alter database open read only;
数据库已更改。
SQL> select * from mbs7_smm.test
--数据与预想有偏差,重新闪回到之前3分钟
SQL> shutdown immediate;
数据库已经关闭。
已经卸载数据库。
ORACLE 例程已经关闭。
SQL> startup mount;
ORACLE 例程已经启动。
Total System Global Area 6847938560 bytes
Fixed Size 2188768 bytes
Variable Size 4697623072 bytes
Database Buffers 2130706432 bytes
Redo Buffers 17420288 bytes
数据库装载完毕。
SQL> flashback database to timestamp to_timestamp('2013-04-25 16:08:44','yyyy-mm
-dd hh24:mi:ss');
闪回完成。
SQL> alter database open;
alter database open
*第 1 行出现错误:
ORA-01589: 要打开数据库则必须使用 RESETLOGS 或 NORESETLOGS 选项
SQL> alter database open resetlogs;
数据库已更改。
SQL>
(三) 闪回总结
恢复的不同场景方案的选择
- 错误的删除表空间 选择基于时间点的还原(取决于归档日志的保留与否);
- 错误的删除用户 选择数据库闪回(取决于闪回日志的保留时间,当然如果要保留长时间的可闪回特性,则需开启闪回日志归档功能,这种应用一般用在追溯历史数据需求比较大的情况下)
- 错误的删除表 选择闪回删除(取决数据是否保存在Oracle回收站,注 如果使用OGG做同步需禁用回收站功能,所以闪回删除功能对我们无效);
- 错误的执行事务,表变更 选择闪回表(取决于事务是否还在UNDO表空间中)
附:简单测试通过,生产环境不建议
可以闪回数据库到正确状态,read only打开先备份准备数据到其他地方,然后shutdown immediateàstartup mountàrecover database就可以回到闪回操作前的最后状态à再把之前导出的数据,导回生产环境,但目前个人没有完全把握,还不太确定生产环境会不会遇到一些其他问题。
--16:50闪回前插入条记录
insert into mbs7_smm.test values(10,sysdate);
commit;
--执行闪回,然后recover,recover后,能看到16:50插入的数据
SQL> flashback database to timestamp to_timestamp('2013-04-25 16:08:44','yyyy-mm
-dd hh24:mi:ss');
闪回完成。
SQL> alter database open read only;
数据库已更改。
SQL> shutdown immediate;
数据库已经关闭。
已经卸载数据库。
ORACLE 例程已经关闭。
SQL> startup mount
ORACLE 例程已经启动。
Total System Global Area 6847938560 bytes
Fixed Size 2188768 bytes
Variable Size 4697623072 bytes
Database Buffers 2130706432 bytes
Redo Buffers 17420288 bytes
数据库装载完毕。
SQL> recover database;
完成介质恢复。
SQL> alter database open;
数据库已更改。
SQL> shutdown immediate;
数据库已经关闭。
已经卸载数据库。
ORACLE 例程已经关闭。
SQL> startup mount;
ORACLE 例程已经启动。
Total System Global Area 6847938560 bytes
Fixed Size 2188768 bytes
Variable Size 4697623072 bytes
Database Buffers 2130706432 bytes
Redo Buffers 17420288 bytes
数据库装载完毕。
SQL> flashback database to timestamp to_timestamp('2013-04-25 16:48:44','yyyy-mm
-dd hh24:mi:ss');
闪回完成。
SQL> alter database open resetlogs;
数据库已更改。
八、 数据块恢复
1) 损坏的数据块发现
在警告日志或EXPDP或日常操作中发现的数据块损坏相关报告时,可以通过如下几种方式进行数据块的恢复。
通过如下脚本可以检查确认块是否损坏,而检查操作是资源敏感的,一般我们通过警告日志或V$database_block_corruption找出需要修复的数据块:
OS下:dbv file=’路径’ blocksize=8192
ANALYZE TABLE emp VALIDATE STRUCTURE ONLINE;
DBMS_REPAIR包的check_object过程
2) 数据块恢复方法
当损坏的数据块不多时,可考虑直接修复数据块,好处是不需要停机,不影响其他数据的访问。如下是几种恢复方法,在方法3不能解决的情况下推荐使用方法1:1) 方法1: 依据备份及归档日志中联机恢复数据块 RECOVER DATAFILE 8 BLOCK 13 DATAFILE 2 BLOCK 19;2) 方法2:
DBMS_REPAIR包的FIX_CORRUPT_BLOCKS and SKIP_CORRUPT_BLOCKS
根据数据块的具体情况可能丢失数据,一般在没备份或允许丢失数据时使用。
3) 方法3:重新导入损坏对象的数据,如损坏的块是索引块,则重建索引
备注:
可以利用归档日志及备份通过RMAN直接联机恢复视图v$database_block_corruption中记录的数据块SELECT * FROM V$DATABASE_BLOCK_CORRUPTION;Rman target /RMAN>RECOVER corruption list;
九、 其他恢复
(一) CRS磁盘备份恢复
RAC环境下,数据库是完全依赖于CRS服务的,如果CRS服务启动失败,数据库也就随之不能对外服务,而CRS服务的核心信息是存放在OCR和VOTING DISK两个磁盘上的,如果这两个磁盘信息丢失将导致整个CRS服务启动失败,所以对这两个磁盘的信息备份恢复尤其重要,以下介绍这两个核心盘的备份恢复方法:
1) OCR磁盘备份:
OCR磁盘信息备份分为手工与自动备份两种,这里介绍常用的自动备份的恢复方式(一般情况下自动备份足够),Oracle 每4个小时对OCR做一次备份,并且保留最后的3个备份,以及前一天,前一周的最后一个备份。 这个备份由Master Node CRSD进程完成,备份的默认位置是grid用户的$ORACLE_HOME/cdata/<cluster_name>目录下,可以通过ocrconfig -backuploc <directory_name> 命令修改到新的目录。 每次备份后,备份文件名自动更改,以反应备份时间顺序,最近一次的备份叫作backup00.ocr。这些备份文件除了保存在本地,DBA还应该在其他存储设备上保留一份,以防止意外的存储故障。查看OCR自动备份(以grid用户登录):[grid@oracle01 ~]$ ocrconfig -showbackuporacle01 2013/12/04 07:05:31 /opt/app/11.2.0/grid/cdata/oracle-cluster/backup00.ocr --最新备份 oracle01 2013/12/04 03:05:30 /opt/app/11.2.0/grid/cdata/oracle-cluster/backup01.ocr oracle01 2013/12/03 23:05:30 /opt/app/11.2.0/grid/cdata/oracle-cluster/backup02.ocr oracle01 2013/12/02 11:05:26 /opt/app/11.2.0/grid/cdata/oracle-cluster/day.ocr oracle01 2013/11/21 03:04:55 /opt/app/11.2.0/grid/cdata/oracle-cluster/week.ocrPROT-25: Manual backups for the Oracle Cluster Registry are not available
2) OCR磁盘恢复
OCR磁盘信息恢复主要用在一些场景上:如误操作导致OCR里的信息被更改,导致CRS或数据库启动异常,或者整个ORC所在ASM磁盘组挂掉,需要重建磁盘组把OCR信息恢复等,以下介绍恢复的方法:
- 模拟OCR信息丢失,CRS服务启动异常:
破坏OCR内容
[root@raw1 bin]# dd if=/dev/zero of=/dev/mapper/volume1p1 bs=1024 count=102400
102400+0 records in
102400+0 records out
检查OCR一致性
[root@raw1 bin]# ./ocrcheck
PROT-601: Failed to initialize ocrcheck
使用cluvfy 工具检查一致性
[root@raw1 cluvfy]# ./runcluvfy.sh comp ocr -n all
Verifying OCR integrity
Unable to retrieve nodelist from Oracle clusterware.
Verification cannot proceed.
使用restore恢复OCR 内容
[root@ bin]# ./ocrconfig –restore /u01/app/11.2.0/grid/cdata/racnode-cluster/backup00.ocr
注意: 使用restore选项只能导入OCR自动产生的物理备份,
import选项只能导入通过export选项导出的的逻辑备份。
再次检查OCR一致性
[root@raw1 bin]# ./ocrcheck
使用cluvfy工具检查
[root@raw1 cluvfy]# ./runcluvfy.sh comp ocr -n all
在所有节点上重新启动CRS
/etc/init.d/init.crs Start注:一般而言,目前我们的环境用于这种操作很少,一般发生在对CRS资源做调整的时候,万一发生了误操作,如不小心把某个资源删除或更改,将会导致CRS某些资源OFFLINE,数据库受到严重影响,这个时候就要用上述方法来进行紧急恢复了。
3) Voting disk恢复:
Voting disk没有备份恢复的概念,一般以磁盘多路径的方式冗余存在即可,目前我们的环境主要放在CRSVOL1-3这三个ASM磁盘组内,如果不幸三个磁盘组都发生意外,一般用replace重建替代解决:
大概步骤:
1首先创建一个新的普通冗余的ASM磁盘组用于存放VOTING DISK:
SQL>create diskgroup CRS normal redundancy
disk ‘/dev/mapper/volume11p1′,’ /dev/mapper/volume12p1′,’ /dev/mapper/volume13p1′ attribute ‘compatible.rdbms’=’11.2.0.0′, ‘compatible.asm’=’11.2.0.0′, ‘au_size’=’4M’;
2关闭CRS后然后以独占模式打开集群
[grid@oracle01 ~]$CRS_HOME/bin/crsctl start crs -excl -nocrs,
3最后重建voting disk,
[grid@oracle01 ~]$CRS_HOME/bin/crsctl replace votedisk +CRS
注:以上方法只是在用在OCR和VOTING DISK分别存储在不同ASM磁盘组的情况下,而目前我们的环境是OCR和VOTING DISK都处于CRSVOL1-3这三个ASM磁盘组内,而ASM是识别底层硬盘的uuid(AIX下是pvid)的,所以如果不幸三个磁盘组都挂掉了,并且不能用回原来的磁盘重建ASM,就只能重构RAC环境了。
(二) ASM元数据备份与恢复
在11g R2中ASM元数据的备份与恢复可用md_backup和md_restore命令实现:
- 适用场景:
- ASM磁盘组所关联的磁盘属主被更改导致ASM磁盘头信息错乱,数据库不能识别,导致启动异常。
- ASM磁盘组意外挂掉了,需要重建一个新的ASM磁盘组后恢复数据,但由于新建的磁盘组,ORACLE识别不了,这需要用原ASM磁盘头元数据进行恢复。
- 使用方法:
备份:
ASMCMD> md_backup /home/grid/asm_backup/tar1_asmdg_bak_20131205 -G CRSDATA
Disk group metadata to be backed up: CRSDATA
-G选项表示指定磁盘组名称,如不指定,默认全部磁盘组元数据备份。
还原:
ASMCMD> md_restore --full -G crsdata /home/grid/asm_backup/tar1_asmdg_bak_20131205
注:目前在TAR1和TAR3已备份两套RAC的ASM磁盘头元信息:
/home/grid/asm_backup/tar1_asmdg_bak_20131205和
/home/grid/asm_backup/tar3_asmdg_bak_20131205
必要时,可用于恢复ASM磁盘头信息。
(三) DATAGUARD切换应用恢复
Dataguard 主备库切换(failover)
当主库由于物理故障或灾难无法启动的时候,需要通过failover把业务切换至备库进行服务,这个过程需人工干预,包括数据库切换,应用修改链接字符等操作。虽然目前11G有Fast-Start Failover特性,但由于该特性是检测备库一旦断电就切换,目前我们环境四大仓库偶尔有断电现象,这个需人工确定是否意外,否则盲目自动切换将带来很多问题,所以暂时不采用这种配置,以下介绍人工进行DG failover切换,恢复业务的方法。
- 旧备库操作:
- 查看归档文件是否连续
SQL> select thread#,low_sequence#,high_sequence# from v$archive_gap;
如果返回的有记录,按照列出的记录号复制对应的归档文件到待转换的standby 服务器。这一步非常重要,必须确保所有已生成的归档文件均已存在于standby 服务器,不然可能会数据不一致造成转换时报错。文件复制之后,通过下列命令将其加入数据字典:(如以上查询无返回记录,直接跳至第二步执行即可)
SQL> ALTER DATABASE REGISTER PHYSICAL LOGFILE 'filespec1';
- 查看归档文件的完整性
SQL> select distinct thread#,max(sequence#) over (partition by thread#) a from v$archived_log;
- 启动failover
SQL> alter database recover managed standby database finish force;
FORCE 关键字将会停止当前活动的RFS 进程,以便立刻执行failover.
- 切换到primary
SQL> alter database commit to switchover to primary;
- 启动数据库到open状态
SQL> alter database open;
- 执行mbs7_wms的序列重建脚本.(这步可选,但需要提前准备序列重建脚本,防止应用报错。)
- 验证数据库可用性(包括登录情况,监听状态等)
- 通知应用开发人员修改数据库链接信息。
- 旧主库操作:
将Failover之后的老的主库 flashback成新primary的standby库:
- 在新主库查出failover时的SCN:
SQL> SELECT TO_CHAR(STANDBY_BECAME_PRIMARY_SCN) FROM V$DATABASE;
TO_CHAR(STANDBY_BECAME_PRIMARY_SCN)
----------------------------------------
172313
- 在old primary库上:
SQL> SHUTDOWN IMMEDIATE;
SQL> STARTUP MOUNT;
SQL> FLASHBACK DATABASE TO SCN172313;
SQL> ALTER DATABASE CONVERT TO PHYSICAL STANDBY;
SQL> SHUTDOWN IMMEDIATE;
SQL> STARTUP MOUNT;
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE
USING CURRENT LOGFILE DISCONNECT;
注:这个旧主库操作是建立在断电后可重新启动数据库或备份有效可介质恢复的情况下,如果主机发生灾难,则需要重新部署新的DG备库.
(四) GOLDENGATE切换应用恢复
这部分详情请查看《7.0存储数据库切换计划》,里面有详细的脚本跟步骤,这里就不再说明了。
十、 数据恢复方式选择总结
如下讨论都是基于归档模式下,对于生产环境,我们的原则是必须开启归档模式:
1) 错误的删除表空间
用户表空间,有备份--------------------------联机完整恢复系统表空间,有备份--------------------------停机mount状态下完全恢复
2) 某表空间数据文件损坏
Ø 非系统表空间数据文件,有备份----------------------联机完全恢复Ø 系统表空间数据文件,有备份-------------------------完全恢复(mount状态),需停机
3) 错误的删除drop表
Ø 闪回功能已开,且回收站功能开启---------------------闪回表删除,联机恢复Ø 不满足闪回表条件,有备份------------------------------进行整库的不完全恢复。会造成整个库的数据丢失,如果生产环境出现这种情况,尽快从其他容灾、模拟或手工补单的方式恢复表;
4) 错误的删除用户及其对象
Ø 闪回功能已开------------------闪回数据库到之前时间点,整库丢失部分数据,需要停机Ø 闪回功能关闭,有备份--------进行不完全恢复,停机 丢数据
5) 错误的DML执行(update,insert,delete)
Ø 符合闪回条件的-------------------闪回查询或闪回表Ø 不符合闪回的,可以尝试Logmnr,找到当时执行的UNDO_SQLØ 尝试从容灾库获取最近数据Ø 进行整库不完全恢复,会造成整个库的数据丢失,如果生产环境出现这种情况,尽快从以上述方面或手工补录实现
6) 错误的Truncate 表
Ø 进行数据库不完全恢复Ø 闪回数据库2种方式,都需要停机,都会造成部分整库数据丢失。当然闪回数据库可以尝试先闪回到truncate之前的时间点àopen read onlyà导出这个表à在recover database。
7) 数据块损坏
Ø 能重建的,直接重建Ø 不能重建的,有备份的通过Blockrecover 进行联机恢复数据块Ø 无备份的尝试DBMS_REPAIR包进行恢复,可能丢失数据 总结起来一句话就是:能闪回的优先闪回,闪回解决不了的优先完全恢复,不完全恢复;恢复总是不可避免的伴随了数据丢失与停机时间的问题,千言万语合理有效的备份是必须保证的,对任何生产环境的数据操作都需要有敬畏之心,避免不必要的人为灾难。

